Advancing WordArt-Oriented Scene Text Recognition: Datasets and Methods
ECCV, 2026
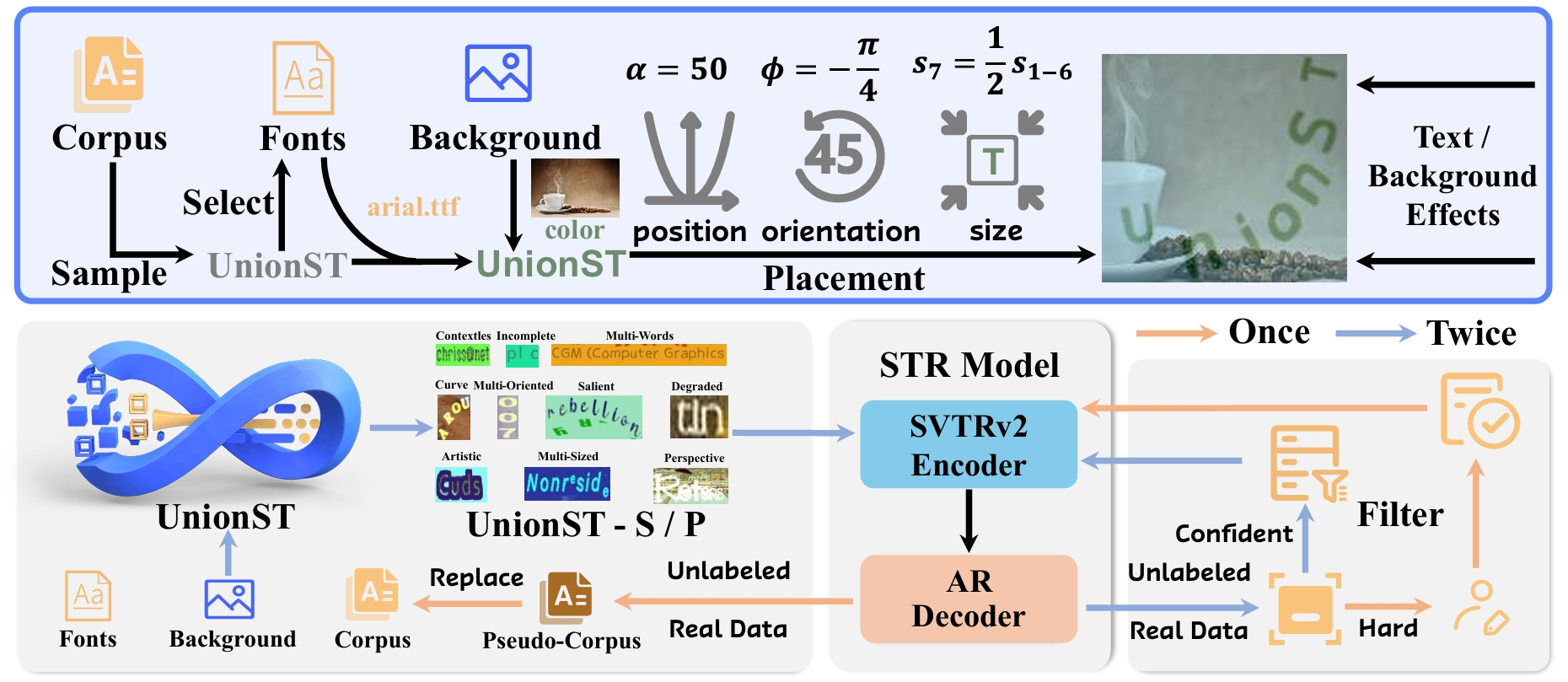
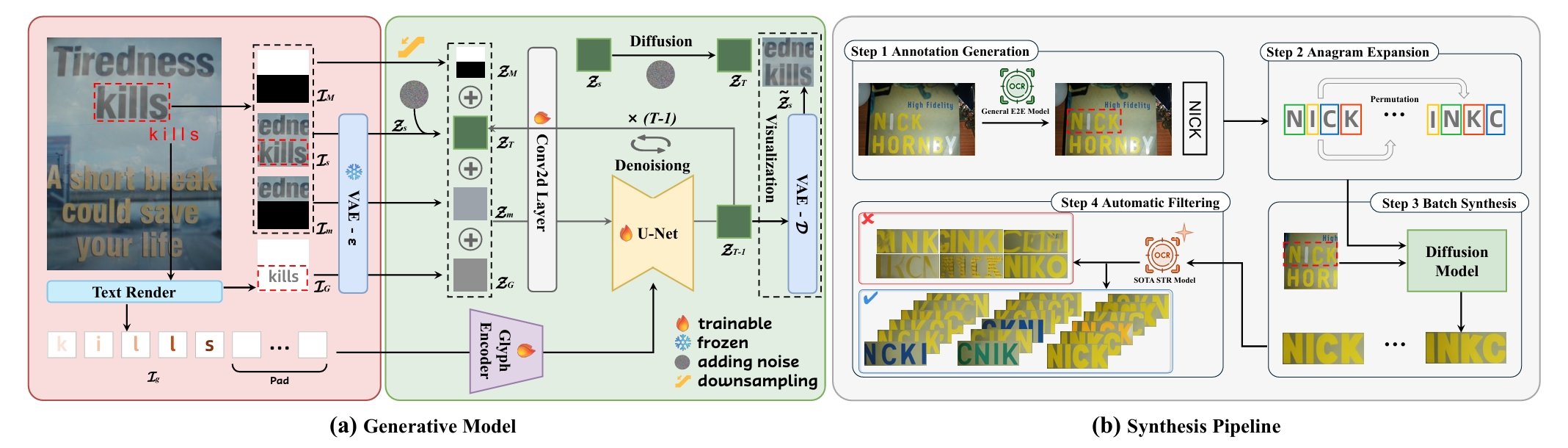
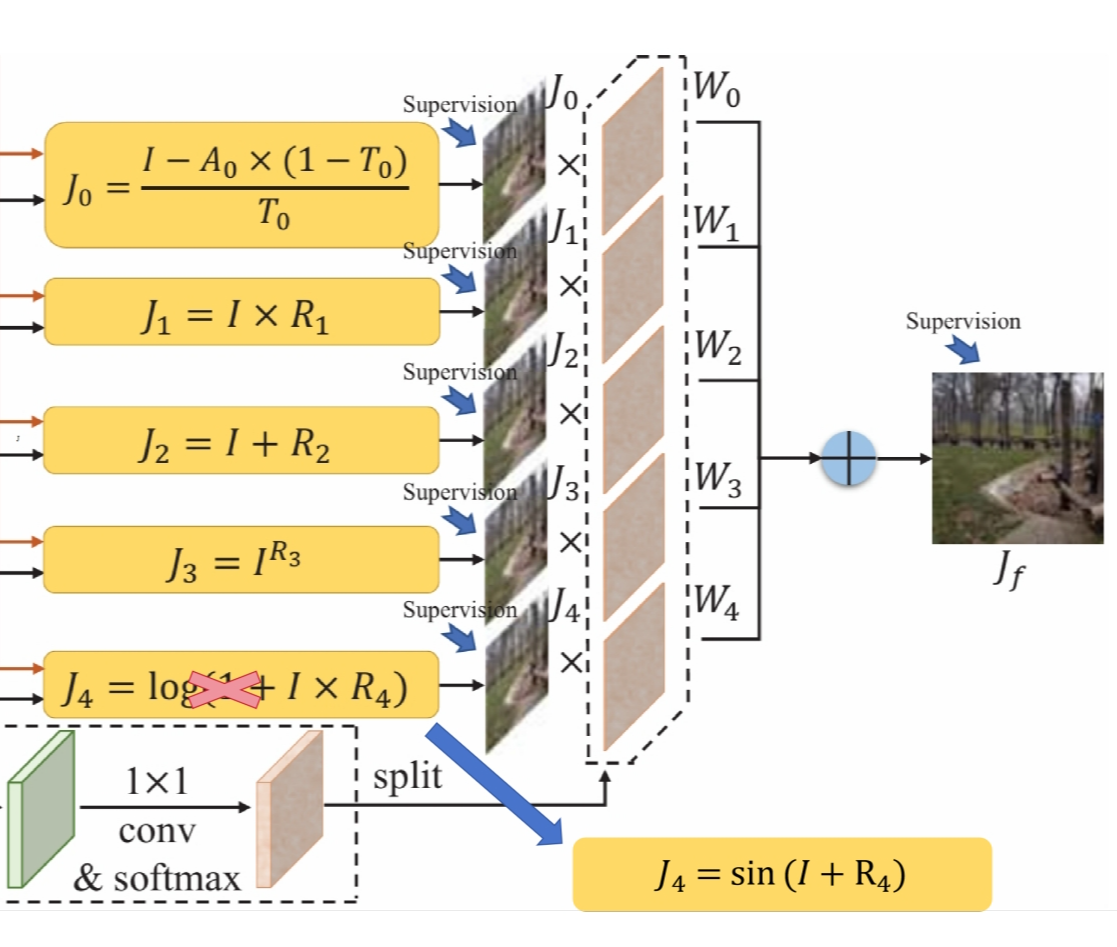
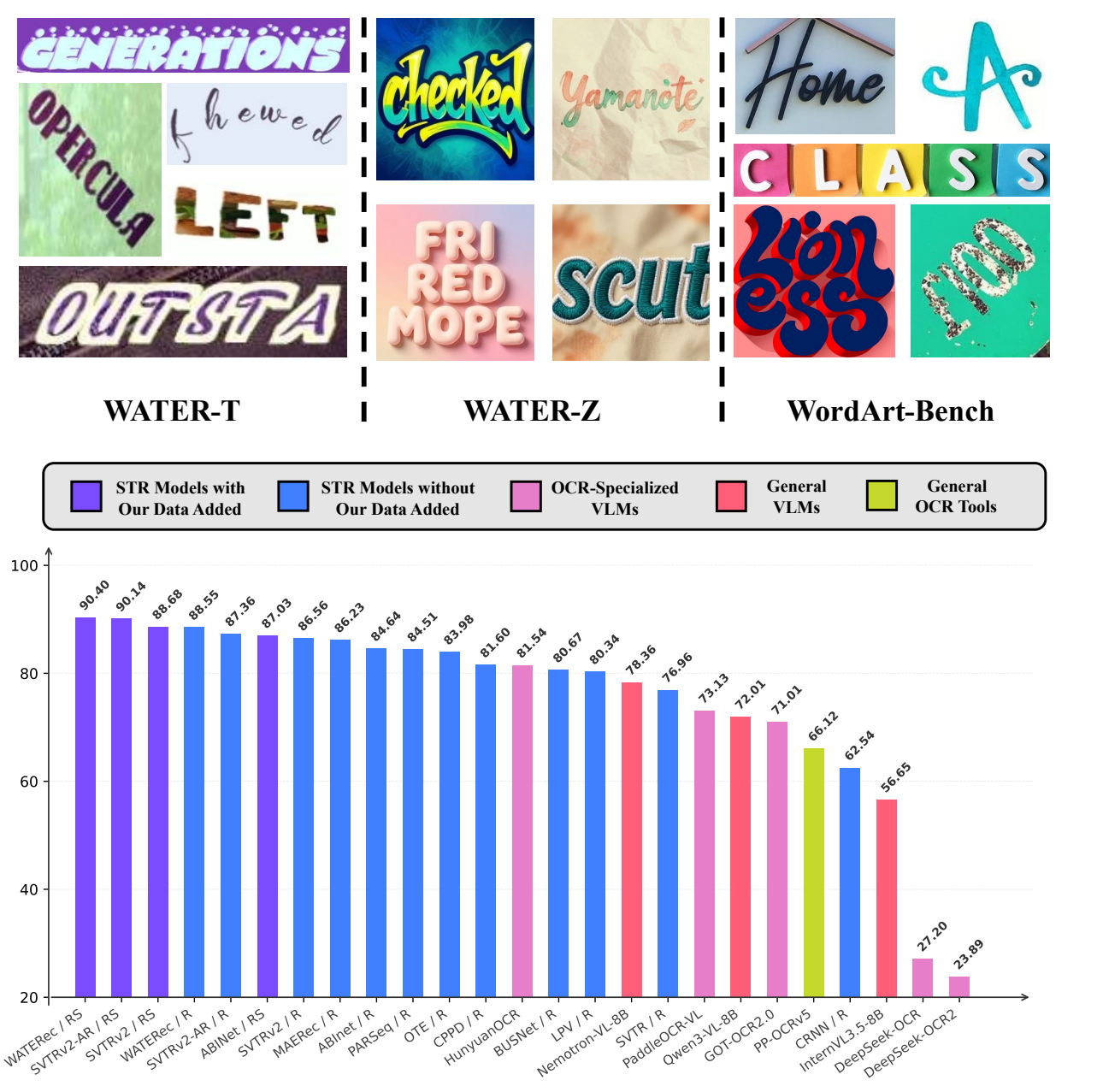
WordArt (artistic text) features highly customized fonts, textures, and layouts, making WordArt-oriented scene text recognition (WATER) far more challenging than general Scene Text Recognition (STR). To advance this task from both data and model perspectives, we construct WATER-S, a 2M synthetic dataset built via an upgraded rendering pipeline (SynthWordArt) and a Qwen3-VL + Z-Image generation pipeline for diverse coverage, and propose WATERec, which couples an arbitrary-shape visual encoder with an autoregressive decoder to break the fixed-template STR bottleneck.